Dask Expr Tpch Dask
By JPatrick Hoefler
TPC-H Benchmarks for Query Optimization with Dask Expressions
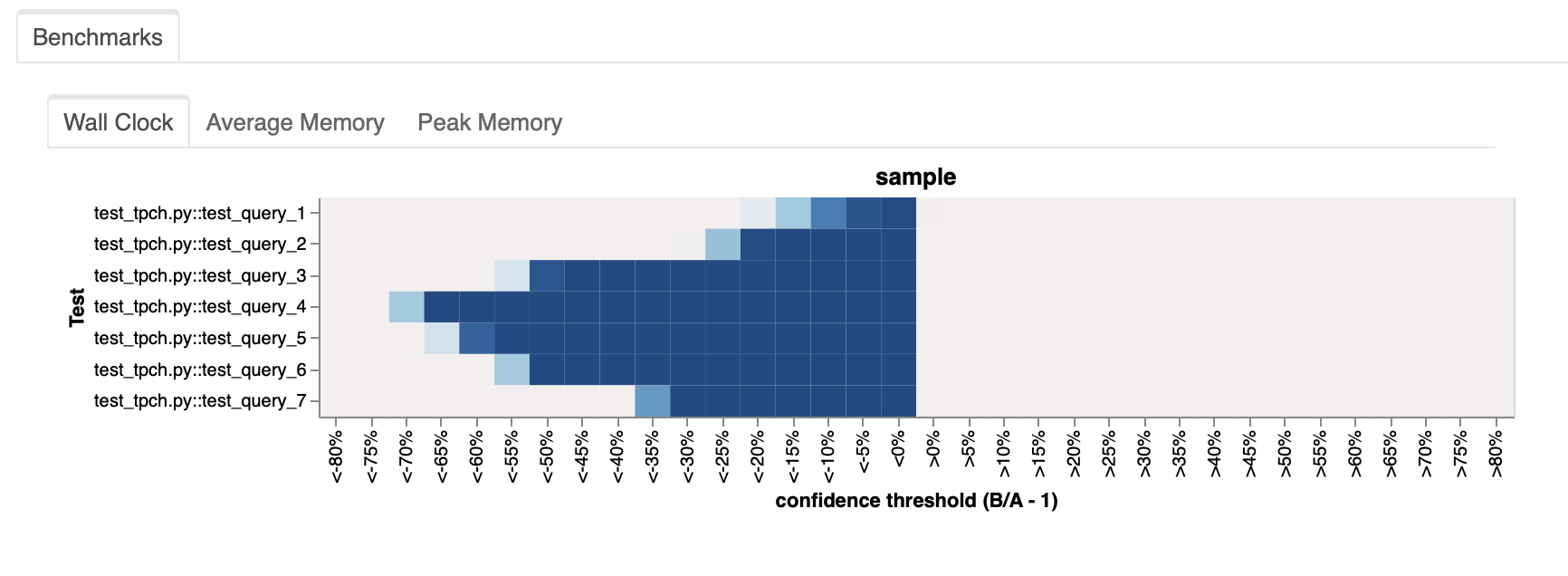
Dask-expr is an ongoing effort to add a logical query optimization layer to Dask DataFrames. We now have the first benchmark results to share that were run against the current DataFrame implementation.
Dask-expr is up to 3 times faster and more memory efficient in its current state than the status quo. This is a very promising result for our future development efforts.
Results
We are comparing Dask 2023.09.02 with the main branch of Dask-expr. Both implementations will use the P2P shuffling algorithm. The results were produced on 100GB of data, e.g. scale 100 for the TPC-H benchmarks. The cluster had 20 workers with 16GB each.
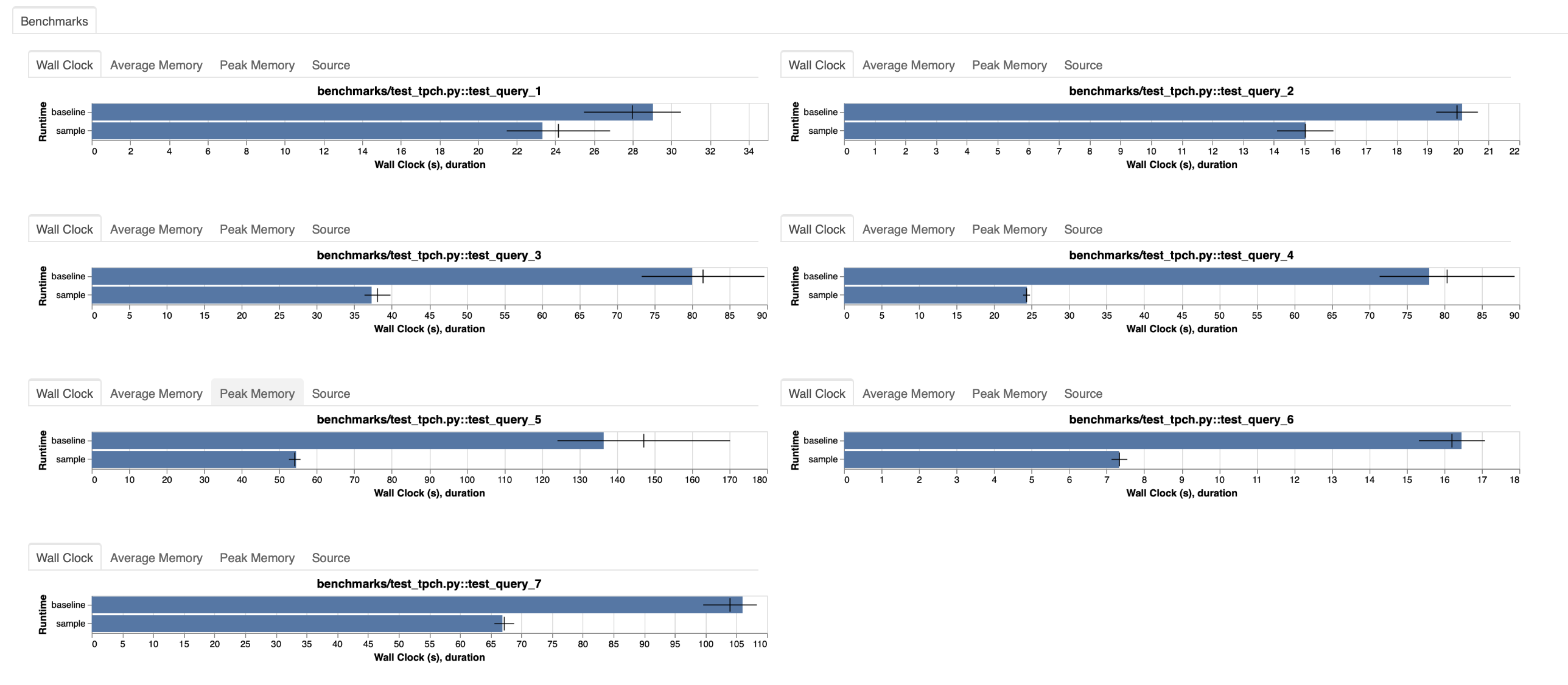
We can see that Dask-expr performs better on every single query, up to a 3-times improvement compared to the status quo.
Dask-expr reorders the query that was given by the user to only execute things that are strictly necessary. It will, for example, drop unnecessary columns and thus reduce the amount of data that is required. We can see that the biggest improvements are for the queries that contain merge operations. These queries write a lot of data to disk and send it over the network. Reducing the size of the data that is transferred has a big impact on the performance.
The reordering results in a reduced memory footprint as well. This is especially helpful for users that struggle with memory pressure on their clusters.
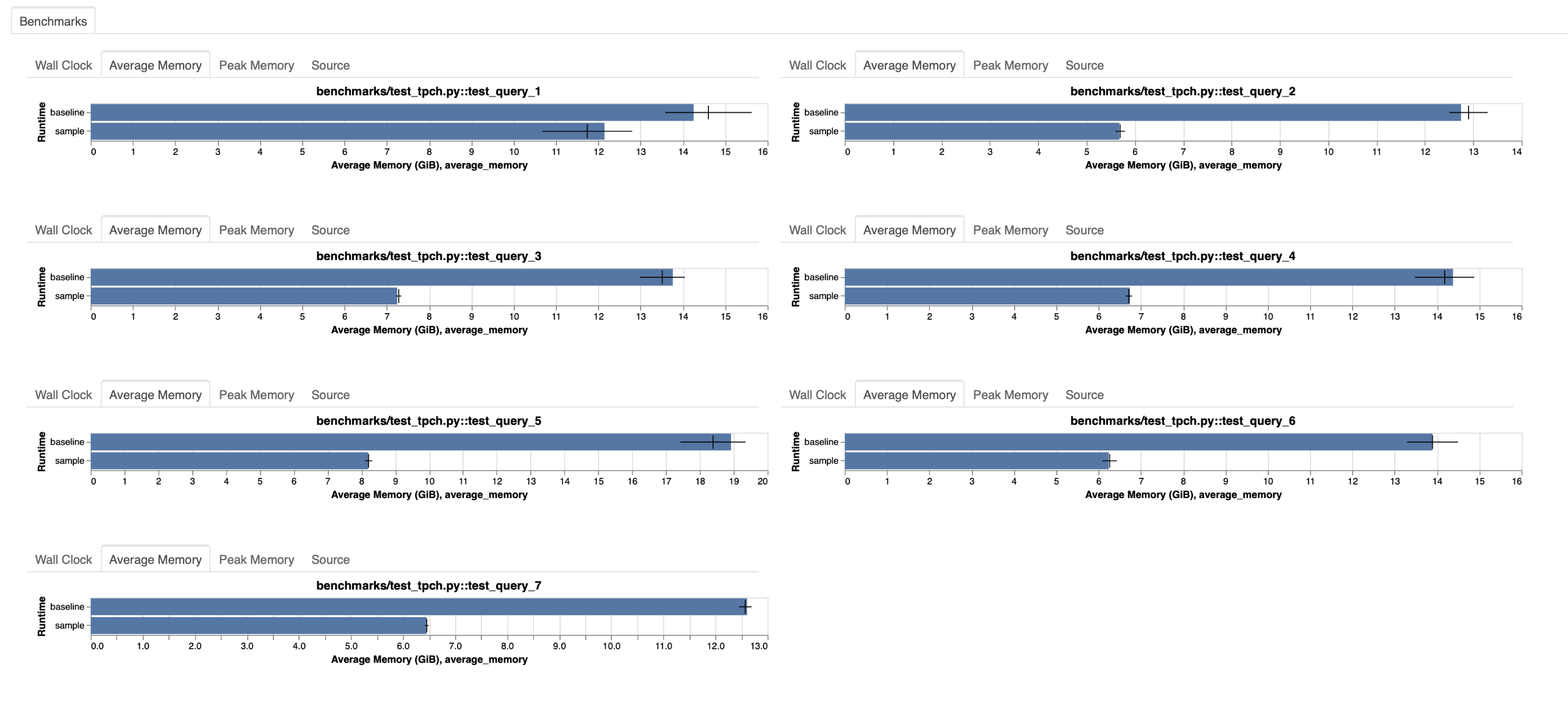
We did another run on 1TB of data, which showed similar results but with a few notable differences:
- Getting Dask-expr to compute the results successfully was very easy. 20 workers very sufficient to compute the results, which is the same number of workers as we used for the 100GB benchmarks.
- The original version needed a bigger cluster with 50 workers and with 32GB memory each.
- Some queries didn’t complete the original version at all, because there were memory spikes on single clusters. Dask-expr was able to complete all queries successfully.
Summarizing, getting these queries to complete was significantly easier with Dask-expr.
These results show us that we are on the right course and motivates us to improve the performance of Dask-expr further. There is still a lot of untapped potential.
About the benchmarks
The TPC-H benchmarks are a set of queries that are commonly used to compare performance of
different databases. Thus, they are very merge and groupby heavy. Historically, the current
implementation didn’t perform very well on these types of queries. The
new P2P shuffling algorithm that was introduced earlier this year and now Dask-expr improves
the performance of Dask a lot.
These queries only capture a small part of the Dask DataFrame API but are helpful to compare performance.
The full implementation of all queries is available here. A single example query is copied below, so you can get a sense of what they look like:
var1 = datetime.strptime("1995-03-15", "%Y-%m-%d")
var2 = "BUILDING"
lineitem_ds = read_data("lineitem")
orders_ds = read_data("orders")
cutomer_ds = read_data("customer")
flineitem = lineitem_ds[lineitem_ds.l_shipdate > var1]
forders = orders_ds[orders_ds.o_orderdate < var1]
fcustomer = cutomer_ds[cutomer_ds.c_mktsegment == var2]
jn1 = fcustomer.merge(forders, left_on="c_custkey", right_on="o_custkey")
jn2 = jn1.merge(flineitem, left_on="o_orderkey", right_on="l_orderkey")
jn2["revenue"] = jn2.l_extendedprice * (1 - jn2.l_discount)
total = jn2.groupby(["l_orderkey", "o_orderdate", "o_shippriority"])[
"revenue"
].sum()
total.reset_index().compute().sort_values(["revenue"], ascending=False).head(10)[
["l_orderkey", "revenue", "o_orderdate", "o_shippriority"]
]
What’s next
We have some additional steps planned over the next couple of weeks. These include:
- Benchmarking Dask expressions against Spark
- Scaling the benchmarks to 1TB, 10TB and 100TB.
We are hoping that we can get additional insights into our implementation and are hoping to identify bottlenecks.
Can I use Dask-expr?
Though Dask-expr is still under active development, the project is in a state where users can try it out. The API coverage is pretty good already. We are still adding new optimizations, so performance will improve in the future.
You can try it out with:
pip install dask-expr
We don’t expect that there exists any hard-to-find-bugs. We did not reimplement any of the algorithms from Dask DataFrame, so we don’t expect hard to identify issues or an unexpected loss of data.
Conclusion
Dask Expressions provides a faster and more memory efficient implementation of Dask DataFrames. The project is still under active development, but it already outperforms the current status quo by a significant margin on the TPC-H benchmarks.
blog comments powered by Disqus