Dask and Pandas and XGBoost Playing nicely between distributed systems
This work is supported by Continuum Analytics the XDATA Program and the Data Driven Discovery Initiative from the Moore Foundation
Summary
This post talks about distributing Pandas Dataframes with Dask and then handing them over to distributed XGBoost for training.
More generally it discusses the value of launching multiple distributed systems in the same shared-memory processes and smoothly handing data back and forth between them.
Introduction
XGBoost is a well-loved library for a popular class of machine learning algorithms, gradient boosted trees. It is used widely in business and is one of the most popular solutions in Kaggle competitions. For larger datasets or faster training, XGBoost also comes with its own distributed computing system that lets it scale to multiple machines on a cluster. Fantastic. Distributed gradient boosted trees are in high demand.
However before we can use distributed XGBoost we need to do three things:
- Prepare and clean our possibly large data, probably with a lot of Pandas wrangling
- Set up XGBoost master and workers
- Hand data our cleaned data from a bunch of distributed Pandas dataframes to XGBoost workers across our cluster
This ends up being surprisingly easy. This blogpost gives a quick example using Dask.dataframe to do distributed Pandas data wrangling, then using a new dask-xgboost package to setup an XGBoost cluster inside the Dask cluster and perform the handoff.
After this example we’ll talk about the general design and what this means for other distributed systems.
Example
We have a ten-node cluster with eight cores each (m4.2xlarges on EC2)
import dask
from dask.distributed import Client, progress
>>> client = Client('172.31.33.0:8786')
>>> client.restart()
<Client: scheduler='tcp://172.31.33.0:8786' processes=10 cores=80>
We load the Airlines dataset using dask.dataframe (just a bunch of Pandas dataframes spread across a cluster) and do a bit of preprocessing:
import dask.dataframe as dd
# Subset of the columns to use
cols = ['Year', 'Month', 'DayOfWeek', 'Distance',
'DepDelay', 'CRSDepTime', 'UniqueCarrier', 'Origin', 'Dest']
# Create the dataframe
df = dd.read_csv('s3://dask-data/airline-data/20*.csv', usecols=cols,
storage_options={'anon': True})
df = df.sample(frac=0.2) # XGBoost requires a bit of RAM, we need a larger cluster
is_delayed = (df.DepDelay.fillna(16) > 15) # column of labels
del df['DepDelay'] # Remove delay information from training dataframe
df['CRSDepTime'] = df['CRSDepTime'].clip(upper=2399)
df, is_delayed = dask.persist(df, is_delayed) # start work in the background
This loaded a few hundred pandas dataframes from CSV data on S3. We then had to downsample because how we are going to use XGBoost in the future seems to require a lot of RAM. I am not an XGBoost expert. Please forgive my ignorance here. At the end we have two dataframes:
df: Data from which we will learn if flights are delayedis_delayed: Whether or not those flights were delayed.
Data scientists familiar with Pandas will probably be familiar with the code above. Dask.dataframe is very similar to Pandas, but operates on a cluster.
>>> df.head()
| Year | Month | DayOfWeek | CRSDepTime | UniqueCarrier | Origin | Dest | Distance | |
|---|---|---|---|---|---|---|---|---|
| 182193 | 2000 | 1 | 2 | 800 | WN | LAX | OAK | 337 |
| 83424 | 2000 | 1 | 6 | 1650 | DL | SJC | SLC | 585 |
| 346781 | 2000 | 1 | 5 | 1140 | AA | ORD | LAX | 1745 |
| 375935 | 2000 | 1 | 2 | 1940 | DL | PHL | ATL | 665 |
| 309373 | 2000 | 1 | 4 | 1028 | CO | MCI | IAH | 643 |
>>> is_delayed.head()
182193 False
83424 False
346781 False
375935 False
309373 False
Name: DepDelay, dtype: bool
Categorize and One Hot Encode
XGBoost doesn’t want to work with text data like destination=”LAX”. Instead we create new indicator columns for each of the known airports and carriers. This expands our data into many boolean columns. Fortunately Dask.dataframe has convenience functions for all of this baked in (thank you Pandas!)
>>> df2 = dd.get_dummies(df.categorize()).persist()
This expands our data out considerably, but makes it easier to train on.
>>> len(df2.columns)
685
Split and Train
Great, now we’re ready to split our distributed dataframes
data_train, data_test = df2.random_split([0.9, 0.1],
random_state=1234)
labels_train, labels_test = is_delayed.random_split([0.9, 0.1],
random_state=1234)
Start up a distributed XGBoost instance, and train on this data
%%time
import dask_xgboost as dxgb
params = {'objective': 'binary:logistic', 'nround': 1000,
'max_depth': 16, 'eta': 0.01, 'subsample': 0.5,
'min_child_weight': 1, 'tree_method': 'hist',
'grow_policy': 'lossguide'}
bst = dxgb.train(client, params, data_train, labels_train)
CPU times: user 355 ms, sys: 29.7 ms, total: 385 ms
Wall time: 54.5 s
Great, so we were able to train an XGBoost model on this data in about a minute using our ten machines. What we get back is just a plain XGBoost Booster object.
>>> bst
<xgboost.core.Booster at 0x7fa1c18c4c18>
We could use this on normal Pandas data locally
import xgboost as xgb
pandas_df = data_test.head()
dtest = xgb.DMatrix(pandas_df)
>>> bst.predict(dtest)
array([ 0.464578 , 0.46631625, 0.47434333, 0.47245741, 0.46194169], dtype=float32)
Of we can use dask-xgboost again to train on our distributed holdout data,
getting back another Dask series.
>>> predictions = dxgb.predict(client, bst, data_test).persist()
>>> predictions
Dask Series Structure:
npartitions=93
None float32
None ...
...
None ...
None ...
Name: predictions, dtype: float32
Dask Name: _predict_part, 93 tasks
Evaluate
We can bring these predictions to the local process and use normal Scikit-learn operations to evaluate the results.
>>> from sklearn.metrics import roc_auc_score, roc_curve
>>> print(roc_auc_score(labels_test.compute(),
... predictions.compute()))
0.654800768411
fpr, tpr, _ = roc_curve(labels_test.compute(), predictions.compute())
# Taken from
http://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html#sphx-glr-auto-examples-model-selection-plot-roc-py
plt.figure(figsize=(8, 8))
lw = 2
plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve')
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()
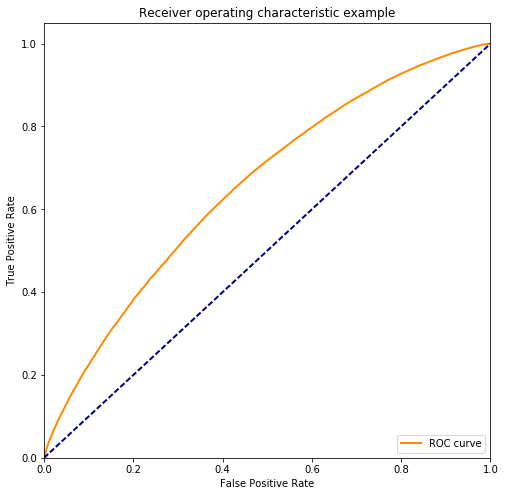
We might want to play with our parameters above or try different data to improve our solution. The point here isn’t that we predicted airline delays well, it was that if you are a data scientist who knows Pandas and XGBoost, everything we did above seemed pretty familiar. There wasn’t a whole lot of new material in the example above. We’re using the same tools as before, just at a larger scale.
Analysis
OK, now that we’ve demonstrated that this works lets talk a bit about what just happened and what that means generally for cooperation between distributed services.
What dask-xgboost does
The dask-xgboost project is pretty small and pretty simple (200 TLOC). Given a Dask cluster of one central scheduler and several distributed workers it starts up an XGBoost scheduler in the same process running the Dask scheduler and starts up an XGBoost worker within each of the Dask workers. They share the same physical processes and memory spaces. Dask was built to support this kind of situation, so this is relatively easy.
Then we ask the Dask.dataframe to fully materialize in RAM and we ask where all of the constituent Pandas dataframes live. We tell each Dask worker to give all of the Pandas dataframes that it has to its local XGBoost worker and then just let XGBoost do its thing. Dask doesn’t power XGBoost, it’s just sets it up, gives it data, and lets it do it’s work in the background.
People often ask what machine learning capabilities Dask provides, how they compare with other distributed machine learning libraries like H2O or Spark’s MLLib. For gradient boosted trees the 200-line dask-xgboost package is the answer. Dask has no need to make such an algorithm because XGBoost already exists, works well and provides Dask users with a fully featured and efficient solution.
Because both Dask and XGBoost can live in the same Python process they can share bytes between each other without cost, can monitor each other, etc.. These two distributed systems co-exist together in multiple processes in the same way that NumPy and Pandas operate together within a single process. Sharing distributed processes with multiple systems can be really beneficial if you want to use multiple specialized services easily and avoid large monolithic frameworks.
Connecting to Other distributed systems
A while ago I wrote a similar blogpost about hosting TensorFlow from Dask in exactly the same way that we’ve done here. It was similarly easy to setup TensorFlow alongside Dask, feed it data, and let TensorFlow do its thing.
Generally speaking this “serve other libraries” approach is how Dask operates when possible. We’re only able to cover the breadth of functionality that we do today because we lean heavily on the existing open source ecosystem. Dask.arrays use Numpy arrays, Dask.dataframes use Pandas, and now the answer to gradient boosted trees with Dask is just to make it really really easy to use distributed XGBoost. Ta da! We get a fully featured solution that is maintained by other devoted developers, and the entire connection process was done over a weekend (see dmlc/xgboost #2032 for details).
Since this has come out we’ve had requests to support other distributed systems like Elemental and to do general hand-offs to MPI computations. If we’re able to start both systems with the same set of processes then all of this is pretty doable. Many of the challenges of inter-system collaboration go away when you can hand numpy arrays between the workers of one system to the workers of the other system within the same processes.
Acknowledgements
Thanks to Tianqi Chen and Olivier
Grisel for their help when building and
testing dask-xgboost. Thanks
to Will Warner for his help in editing this
post.
blog comments powered by Disqus